
前言
记得以前直播的时候有一个东西叫做点歌姬,然后他其中有一个功能就是把点歌姬里面正在播放的音乐存到一个txt文件里面,然后obs就可以实时读取这个文件然后展示到直播画面里面。但是如果我不想要那个点歌的功能,也不想用点歌姬,只是想把我目前在网易云里听的歌的名字展示到屏幕上的话,就比较棘手了,而下面是我的探索之路。
探索
第一次尝试
我第一个想到的是可以获取当前窗口的名字,因为网易云在播放音乐的时候会把当前播放的音乐作为窗口标题。
经过一些搜索之后我找到了stackoverflow上的这个帖子:https://stackoverflow.com/questions/31278590/get-the-title-of-a-window-of-another-program-using-the-process-name
这个帖子里面其中一个回答就给出了通过进程名获取窗口标题的方法,而这正是我们所需要的。
里面的代码长这样:
import sys
import os
import traceback
import win32con as wcon
import win32api as wapi
import win32gui as wgui
import win32process as wproc
# Callback
def enum_windows_proc(wnd, param):
pid = param.get("pid", None)
data = param.get("data", None)
if pid is None or wproc.GetWindowThreadProcessId(wnd)[1] == pid:
text = wgui.GetWindowText(wnd)
if text:
style = wapi.GetWindowLong(wnd, wcon.GWL_STYLE)
if style & wcon.WS_VISIBLE:
if data is not None:
data.append((wnd, text))
#else:
#print("%08X - %s" % (wnd, text))
def enum_process_windows(pid=None):
data = []
param = {
"pid": pid,
"data": data,
}
wgui.EnumWindows(enum_windows_proc, param)
return data
def _filter_processes(processes, search_name=None):
if search_name is None:
return processes
filtered = []
for pid, _ in processes:
try:
proc = wapi.OpenProcess(wcon.PROCESS_ALL_ACCESS, 0, pid)
except:
#print("Process {0:d} couldn't be opened: {1:}".format(pid, traceback.format_exc()))
continue
try:
file_name = wproc.GetModuleFileNameEx(proc, None)
except:
#print("Error getting process name: {0:}".format(traceback.format_exc()))
wapi.CloseHandle(proc)
continue
base_name = file_name.split(os.path.sep)[-1]
if base_name.lower() == search_name.lower():
filtered.append((pid, file_name))
wapi.CloseHandle(proc)
return tuple(filtered)
def enum_processes(process_name=None):
procs = [(pid, None) for pid in wproc.EnumProcesses()]
return _filter_processes(procs, search_name=process_name)
def main(*args):
proc_name = args[0] if args else None
procs = enum_processes(process_name=proc_name)
for pid, name in procs:
data = enum_process_windows(pid)
if data:
proc_text = "PId {0:d}{1:s}windows:".format(pid, " (File: [{0:s}]) ".format(name) if name else " ")
print(proc_text)
for handle, text in data:
print(" {0:d}: [{1:s}]".format(handle, text))
其实我们可以完全不用管里面的原理就拿来用,但是出于求知的精神我们还是稍微看一下具体源码的内容。
看主函数里面的内容,首先它是尝试从命令行参数里面获取需要获取窗口标题的进程名。然后 enum_processes 被调用,我们执行一下这个函数看看这个函数有什么作用:

看起来这个函数的作用是根据这个进程名,输出所有能找到的进程的pid和对应的位置。
而这个函数的代码也非常简单,就只是对win32api的调用。并通过 _filter_processes 过滤掉不能正常打开的进程和不能获取进程名的进程,并把进程可执行文件的路径和进程名相对比,最后把符合要求的进程pid和路径放入返回列表中。
然后我们看到主函数里面对元组里面每一个pid调用了一下 enum_windows_proc 这个函数。我们也用我们刚刚得到的pid来调用一下这个函数看看:

看起来我们的目标已经达到了,而且我们一看这个函数的内容也是对win32api的一些调用。
我们看看对剩余的pid调用这个函数试试:
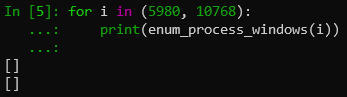
看起来只是客户端执行一些其他操作的进程,并不是播放器的进程,所以我们只需要把这个列表不为空的pid作为输出就行了。
那么接下来的工作应该就非常简单了,只是把窗口标题变化的时候写入文件就可以了,但是为什么这一个小节的标题是第一次尝试而不是成功的实践呢?
此方法存在的问题
网易云的客户端有一个功能是可以把客户端缩小,然后始终置顶。我们尝试在这个状态下调用 enum_windows_proc 函数:

看起来我们遇到了一些麻烦。当播放器变成迷你播放器的时候他的标题也变成了“迷你播放器”,但是这并不是我们想要的。
所以就由于这个原因我们放弃了这个方法。不过获取窗口标题这个方法我们也许可以以后在别处用到。
第二次尝试
上述方法无效之后我尝试通过查看网易云数据文件里面哪个文件在切换歌曲会立即更新来找到可能包含正在播放歌曲的信息的文件:
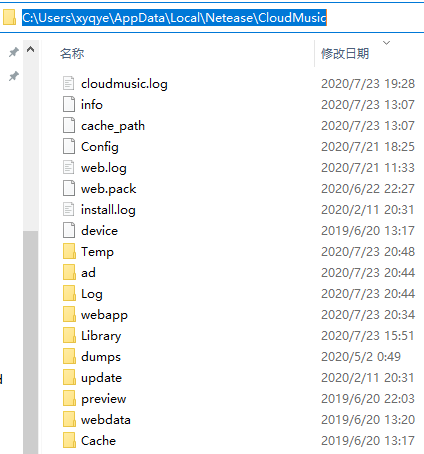
我们发现客户端的日志文件会在换歌之后会立即更新,所以里面有可能就包含有当前播放歌曲的信息。
我们播放一首歌,然后打开日志查找试试:

看来非常有希望,我们确实在日志文件里面找到了当前播放的歌曲。但是问题是这里面显示的是一个本地目录,而且是歌曲下载目录,那么我们尝试播放一个没有下载过的歌曲试试:

嗯,这一招似乎不太行了。
但是网易云每首歌有一个独有的id,这个id总应该和在线不在线没关系了。
我们通过分享分享链接获取这首歌的id:
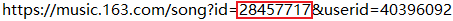
可以看到我们获取到了这首歌的id,让我们在日志文件里面搜索这个id试试:

看起来能行,只需要一个正则表达式就可以提取到id了。
所以这种方法的大概流程就是:
- 当日志文件更新的时候读取更新的部分
- 通过正则表达式提取歌曲id
- 通过歌曲id获取歌曲名
等等,通过歌曲id获取歌曲名?这个问题似乎我们还没有涉及到。
通过一阵子的查找,我发现有两个方法可以获得歌曲id对应的歌曲信息,一个是通过网易云客户端保存在本地的sqlite数据库获得,第二种是通过网易云的web api获得( http://music.163.com/api/song/detail/?id={id}&ids=%5B{id}%5D ).
但是这样未免把程序做得太为复杂了,所以我们放弃通过日志的方法。
最后尝试
在我浏览日志文件的时候我发现了这一行:

很明显,这个文件是存历史记录的,而且很有可能是存播放历史记录的。所以我们可能就能够通过获取这个历史记录的最新记录来获得当前播放的歌曲。
当我们打开文件之后发现文件内容是这样的:


这明显是json格式或者说类json格式。
然后我们发现这个列表的第一个字典元素就包含了我们当前播放的歌曲。那么这可能就是最终的解决方案了,
实时读取文件
一个有效的方法是每隔一段时间查看文件的修改日期,如果修改日期改变的话才读取文件,然后再更新储存了当前播放歌曲的文件。
实际上有一个库叫做watchdog可以监听系统事件,其中也包括文件的修改,这样就不用我们重复造轮子了
import sys
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class LoggingEventHandler(FileSystemEventHandler):
def on_modified(self, event):
super(LoggingEventHandler, self).on_modified(event)
what = 'directory' if event.is_directory else 'file'
print(f'Modified {what}: {event.src_path}')
def main():
path = sys.argv[1] if len(sys.argv) > 1 else '.'
event_handler = LoggingEventHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
if __name__ == "__main__":
main()
通过上述的代码,我们就可以监听当前目录下或者给定参数目录下的文件修改事件了。
获取history文件所在目录
我们可以通过以下表达式获取history文件所在的目录。
path = os.path.join(os.path.expanduser('~'), r'AppData\Local\Netease\CloudMusic\webdata\file')
解析history文件
我们发现这个history文件一般都有200KB左右,当历史记录更多的时候可能更大。如果每次这个文件更改都解析整个json未免有点低效了,所以我们需要找个办法只解析这个json列表里面的第一个字典。
history文件中第一个字典长这样(history中整个文件都只有一行):
{'track': {'album': {'id': 36634131,
'name': 'けいおん!はいれぞ!「Come with Me!!」セット',
'picId': '109951163048673023',
'picUrl': 'https://p4.music.126.net/e1n_xjLFAm_GY8ZETmka4g==/109951163048673023.jpg',
'alias': [],
'transNames': []},
'alias': [],
'artists': [{'id': 161782, 'name': '放課後ティータイム', 'tns': [], 'alias': []}],
'commentThreadId': 'R_SO_4_514765041',
'copyrightId': 663018,
'duration': 253280,
'id': 514765041,
'mvid': 10850421,
'name': 'NO, Thank You!',
'cd': '1',
'position': 21,
'ringtone': None,
'rtUrl': None,
'status': 0,
'pstatus': 0,
'fee': 0,
'version': 8,
'songType': 0,
'mst': 9,
'popularity': 45,
'ftype': 0,
'rtUrls': [],
'yunSong': {'uid': 40396092,
'nickname': '',
'songName': 'NO, Thank You!',
'album': 'けいおん!はいれぞ!「Come with Me!!」セット',
'artist': '放課後ティータイム',
'coverId': '109951165018150110',
'fileExt': '.mp3',
'bitrate': 326},
'hMusic': {'bitrate': 320000,
'dfsId': 0,
'size': 10133464,
'volumeDelta': -39100},
'mMusic': {'bitrate': 192000,
'dfsId': 0,
'size': 6080096,
'volumeDelta': -36700},
'lMusic': {'bitrate': 128000,
'dfsId': 0,
'size': 4053412,
'volumeDelta': -35500},
'privilege': {'id': 514765041,
'version': '0-0-0-326-326-999-999-7-1-1-1',
'fee': 0,
'payed': 0,
'status': 0,
'maxPlayBr': 326,
'maxDownBr': 326,
'maxSongBr': 999,
'maxFreeBr': 999,
'sharePriv': 7,
'commentPriv': 1,
'subPriv': 1,
'cloudSong': 1,
'toast': False,
'flag': 136,
'now': 1595490687000},
'commentCount': 151},
'id': '514765041_1_33803710_1595480877683',
'tid': 514765041,
'program': None,
'fid': '1',
'data': '33803710',
'href': '/m/playlist/?id=33803710&rid=A_PL_0_33803710&fromSource=1',
'text': '我喜欢的音乐',
'nickName': '辣条ii',
'userId': 40396092,
'fromButton': False,
'specialType': 5,
'startlogtime': 1595555807539,
'loaderr': False,
'playedTime': 0,
'lastTime': 0,
'logDuration': 0,
'isCloudMusic': False,
'lastPlayInfo': {'bitrate': 320,
'retJson': {'id': 514765041,
'url': 'http://m8.music.126.net/20200502162942/dcb351459e414e759c04a4f0e3366c26/ymusic/6e3f/53bf/0cdc/c86b892db7c67f19604d2a77970f181e.mp3',
'br': 320000,
'size': 10133464,
'md5': 'c86b892db7c67f19604d2a77970f181e',
'code': 200,
'expi': 1200,
'type': 'mp3',
'gain': 0,
'fee': 0,
'uf': None,
'payed': 0,
'flag': 0,
'canExtend': False,
'freeTrialInfo': None,
'level': 'exhigh',
'encodeType': 'mp3'}},
'playType': 4,
'playBrt': 320,
'playedTimeFromNative': 0,
'aiRcmd': False,
'qid': '514765041_1_33803710',
'time': 1595555807594}
我们可以发现里面每个字典的长度都是2000上下,如果保险起见那么为了能够解析到一个完整的字典,至少也要读取3000个字符的样子。
尝试使用正则
经过进一步考虑我们发现其实只需要读取前400个字符左右,然后用正则表达式 r'”name”:”(.*?)”‘来匹配就可以分别得到专辑名,艺术家和歌曲名了。

为了保险起见,我们读取前800个字符。
所以从history解析正在播放的歌曲的代码就是这样了:
pattern = re.compile(r'"name":"(.*?)"')
def get_playing(path):
with open(path, encoding='utf-8') as f:
new_content = f.read(800)
return pattern.findall(new_content)
但是经过一番测试之后发现有些歌会没有专辑名,导致上面的正则表达式只能匹配到一个。
还是决定用json解析
我们测试完了正则表达式之后发现并不是很可靠,于是还是退回到用json解析的方法来。
但是我们又遇到了一个新的问题。
history文件里的json结构大概是这样的:
[{"a":"...", "b":"...", ...}, {"c":"......", "d":"....", ....}, ...]
这个列表里面的每个字典的长度是不定长的,我们需要想办法只把第一个字典的字符串送入json解析器里面,但是这有点复杂了。
经过搜索,我们发现了我们可以使用如下的代码来从字符串中解析第一个出现的完整json,忽略额外的字符串。
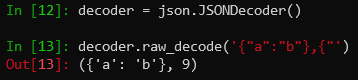
这里的raw_decode方法返回元组里第一个元素是解码器找到的第一个完整json,第二个元素是解析了的字符串长度。这个在流式传输的时候还挺有用的,这里我们就把它用作history文件的解析。
def get_playing(path):
track_info = dict()
with open(path, encoding='utf-8') as f:
read_string = f.read(3200)
for _ in range(4):
try:
read_string += f.read(500)
decoded_json = decoder.raw_decode(read_string[1:])
track_info.update(decoded_json[0])
break
except json.JSONDecodeError:
pass
if not track_info:
return None
track_name = track_info['track']['name']
artist_list = [i['name'] for i in track_info['track']['artists']]
return track_name, artist_list
这里我们首先读取3200个字符,然后除去第一个字符送入json解析器,如果产生错误的话就再加500个字符,然后再次解析,尝试四次直到解析出来。
然后我们就可以从解析出来的字典里面获取歌曲名和艺术家列表了。
所以最后我们的程序就是这样了:
import os
import time
import json
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
decoder = json.JSONDecoder()
def get_history_file():
path = os.path.join(os.path.expanduser('~'), r'AppData\Local\Netease\CloudMusic\webdata\file')
if os.path.exists(path):
return path
else:
print('cloudmusic data folder not found')
exit(1)
def get_playing(path):
track_info = dict()
with open(path, encoding='utf-8') as f:
read_string = f.read(3200)
for _ in range(4):
try:
read_string += f.read(500)
decoded_json = decoder.raw_decode(read_string[1:])
track_info.update(decoded_json[0])
break
except json.JSONDecodeError:
pass
if not track_info:
return None
track_name = track_info['track']['name']
artist_list = [i['name'] for i in track_info['track']['artists']]
return track_name, artist_list
class LoggingEventHandler(FileSystemEventHandler):
def __init__(self):
self.file_size = 0
def on_modified(self, event):
super(LoggingEventHandler, self).on_modified(event)
path = event.src_path
if path.endswith(r'webdata\file\history'):
current_size = os.path.getsize(path)
if current_size != self.file_size:
self.file_size = current_size
for _ in range(5):
try:
song, artists = get_playing(path)
with open('playing.txt', 'w', encoding='utf-8') as f:
playing = f'{song} - {" / ".join(artists)}'
print(playing)
f.write(playing)
break
except PermissionError:
time.sleep(1)
def main():
path = get_history_file()
event_handler = LoggingEventHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
if __name__ == "__main__":
main()
再补一条,在程序初始时捕获完网易云音乐进程号以后 -> 记得随便点一首歌暂停然后即可,这样再执行那段代码,接着就可以获取歌曲名了。
没什么可说的–搞定了

思路就是:
1.开始的时候存储进程号–当打开网易云客户端时,先把歌曲列表清空–这样能使得还原程序本身窗体名称。
2. 如果查询时出异常了,说明程序关闭了.
3.通过枚举窗体时,匹对进程号来获取窗体名。如果想要萃取歌曲完整名称,可以通过正则表达式 “.+ – .+” 把不匹配的跳过,把匹配的留下。(但是千万记得要把匹配到的及时送出去,不要在枚举内搞,容易出现双重结果)。
这样的做法完全没有必要打开窗体显示,甚至挂在后台都行,但是最重要的一点就是一定要保证两条:
1. 初始时要通过程序本身的窗体名来获取窗体的句柄 -> 再获取进程号进行存储,供给枚举匹配时使用。
2. 程序要保证打开,不能关闭。
哈哈哈有思路了
理论上只要,通过枚举窗体时获取到窗体的进程ID,和我网易云程序的进程ID一匹对就可以了。
很难实现 。
。
我采用Java 的第三方api -> jna 来间接性的调用win32.
但是遇到了难题:
1. 如果枚举所有窗体的标题,但是网易云的标题是直接显示的,没有任何标志,很难萃取。
2. 获取指定窗体,音乐的窗体名是随时发生变化的,也超难~
我的网易云隔了不知多久才写一次history,切歌以后这个文件并不改变,应该是失效了
我转用YesPlayMusic了,所以没有在维护这个脚本了。很抱歉